
By Luna Beerden
Hi! I’m Luna, a former student in Egyptology and Digital Humanities at the KU Leuven. During my internship at KU Leuven Libraries in Spring to Summer 2022, I worked on the enhancement of data dissemination of the library’s digitized collections. Because of my background in Egyptology, the collection of 3485 glass diapositives with an Egyptological theme (part of a much larger collection of glass slides) were chosen as a case study. The topics of these diapositives varies greatly: they range from daily life and travel photography, over educational slides with views of monuments and museum artifacts, to slides depicting (at that time) ongoing excavations. Little information is known on the origin of the collection or the exact age of the slides, although they were surely used to teach Egyptology at the university well into the 1970s.
Considering the sheer size and variety of the collection, not all glass diapositives were pushed to the Wiki Environment at once. The primary focus were the slides depicting the French excavations in El-Tod (Louvre Museum, 1936) and Medamud (IFAO, 1925-1932). The selection of these batches was made based on their perceived unicity, with excavation slides estimated to be rarer than educational slides. Further, a third batch of slides depicting museum artifacts was prepared for upload, chosen to highlight the connectivity with several holding institutions of important Egyptological collections in a way to further improve the visibility of the collection of KU Leuven Libraries. This is not to say, however, that the other glass diapositives are perceived in any way less important.

Considering the Library’s open data policy and the work performed by previous Digital Humanities’ interns within this setting, I did not have to start from scratch, but could rather build upon their work and experiences. This blog post takes a closer look at the research process and practicalities that eventually led to the creation of the pilot study ‘Wikidata and Wikimedia Commons as Linked Data Hubs: Dissemination of KU Leuven Libraries’ digitized collections through the Wiki Environment’.
Metadata Dissemination – the Wiki Environment
Before any work was started on the data itself, it was essential to first establish if the Wiki Environment was a good fit for the digitized collections of KU Leuven Libraries. An extensive literature review was performed where both platforms, being Wikidata and Wikimedia Commons, were critically examined and their added value to the libraries’ existing workflows was determined. The result of this review proved positive, with the main advantages of use being the platforms’ multilingual and centralised character, their position as a linked data hub, the high level of engagement compared to the libraries’ own database PRIMO, and the existence of specialised query and visualisation tools.
Although uploading files to Wikimedia Commons has been going on for some time, there’s been a recent shift towards Wikidata because of its linked open data structure, which is hidden behind a user-friendly interface, data models, and tools, all concealing these technological complexities[1]. In short, Wikidata builds upon RDF triplets, consisting of an object, a property, and a subject that all receive a unique identifier (QIDs and PIDs). Qualifiers can be added to specify or provide additional information to a statement, and references to back up the information given[2]. Due to this linked data structure, different data sources can be querried simultaneously with the Wikidata Query Service (WDQS) which allows users to pose more complex questions and essentially transforms Wikidata into an authority hub centralising and connecting metadata from collections worldwide[3].
One of the key drawbacks of the Wiki Environment that has to be addressed, is the absence of standardization combined with the lack of documentation on the ‘Wiki-way’ to structure metadata, especially for Wikidata. Therefore, a lot of research and comparison was performed during this internship to understand best practices and to create guidelines to be implemented in future work by KU Leuven Libraries, and by extension the GLAM sector.
Case study – Glass diapositives Egyptology, KU Leuven Libraries
Data handling was performed in OpenRefine, a free, open source tool that offers the possibility to clean and transform large amounts of data with minimal effort and that is closely linked to the Wiki Environment. Prior to data cleaning, the metadata model and the precise content of the raw metadata had to be closely examined and matched with the Wiki Environment. The entities corresponding to the metadata values to be pushed were determined by going through all Wikidata properties and Wikimedia Commons templates, and by investigating uploads of glass diapositives by other libraries and holding institutions. One of the main difficulties of data mapping to both platforms was the limitation in Wikidata properties and Wikimedia Commons templates to choose from. In essence, the metadata of the collection was so rich that not all information could be easily mapped. Instead of leaving certain data out, an individual solution was sought for all fields, and metadata modification took place to enhance the usability and readability of the data.
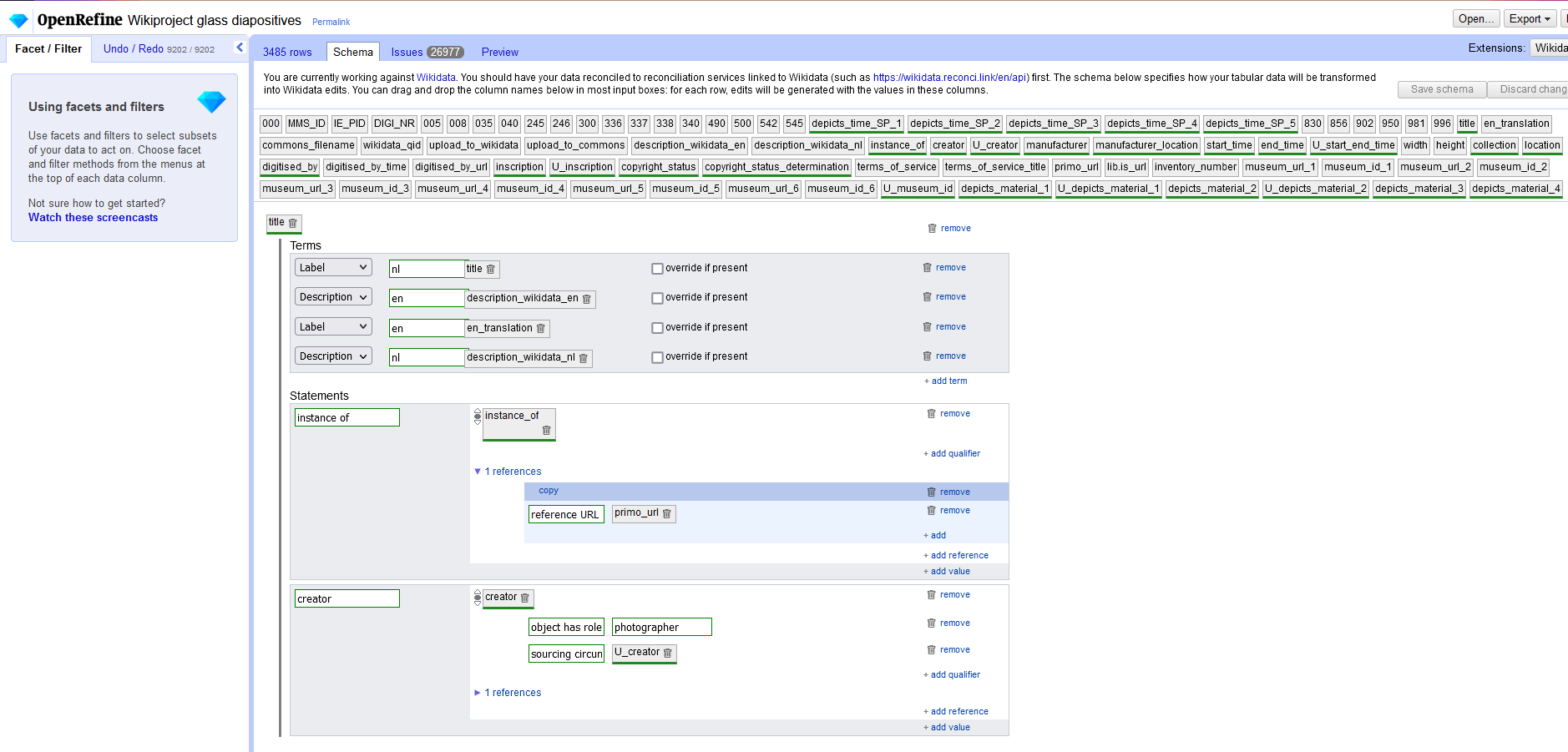
With data mapping and cleaning completed, it was possible to start data reconciliation; a semi-automated process where metadata is matched to data from an external source, in this case Wikidata. All matches had to be checked manually, as the pattern matching performed by OpenRefine does not deliver perfect results. Reconciliation was carried out for all columns in the dataset, excluding unique metadata such as inventory numbers and URLs. Pushing the metadata to Wikidata, required a Wikibase scheme to be prepared, which can be carried out in the Wikidata extension of OpenRefine (see figure 2). Fundamentally, a Wikibase scheme represents the structure of the Wikidata items to be created and consists of a combination of terms and statements. All relationships could easily be mapped by selecting the previously determined Wikidata properties with their associated values and qualifiers as statements, and dragging the associated, reconciled columns of the OpenRefine project from the top of the page. Once the scheme was completed, it was saved for export to Quickstatements and for potential reuse during future uploads. The Quickstatements tool was selected for metadata upload as it allows for more control of batch uploads, with a list of previous uploads being available, errors being flagged, and reversion being easily executable. An export to Quickstatements can be commenced through the Wikidata extension of OpenRefine, creating a .TXT file with V1 commands that should be copy-pasted in the Quickstatements tool (see figure 3).
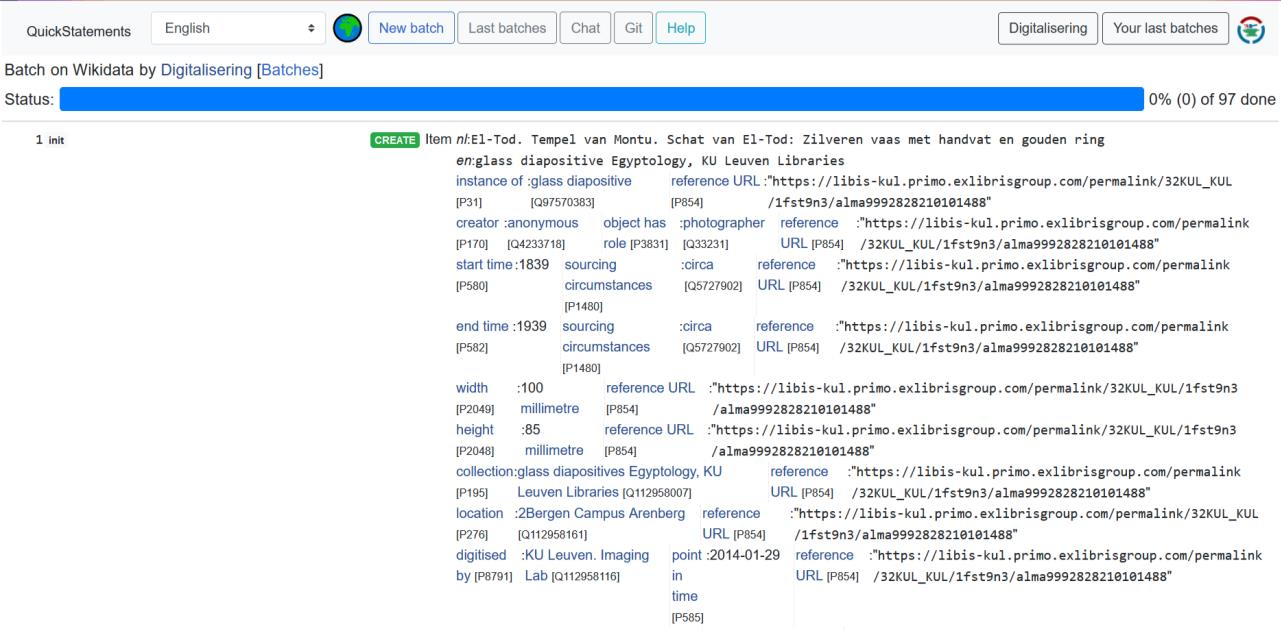
A main issue that occurred when pushing the metadata to Wikidata, was the absence of titles for the created Wikidata items when querying the platform with any language setting other than Dutch. Not only did this lead to a decreased readability for users but hampered the item’s findability as Dutch search terms were required for the glass diapositives to appear in the user’s search results. To solve this, English translations were created of the titles of all glass diapositives using the translators 5.4.1 library in Python (see figure 4), and added to Wikidata via Quickstatements. An example of a Wikidata item created is shown in figure 5.


Now the metadata of the glass diapositives was uploaded to Wikidata, it was time to push the photographs and their metadata to Wikimedia Commons as well. First, the exifdata present in the images had to be complemented with information from the descriptive metadata as a safety measure against misuse and misattribution. The choice of XMP tags (Extensible Metadata Platform), or metadata to add, was inspired by the webinar on exifdata organised by meemoo and a case study on Wikimedia Commons by the Groeningemuseum in Bruges.[4] ExifTool, a Perl library and command-line application to adapt metadata, was chosen to overwrite the exifdata that was already present in the images (see figure 6).

Using the Pattypan tool, the batch upload of all images with their updated exifdata was started, following a custom template based on the photography template offered by Wikimedia Commons (see figure 7). All data was uploaded under the Wikimedia Commons category Glass diapositives Egyptology, KU Leuven Libraries with parent categories Digitised collections of KU Leuven Libraries and Historical Photographs of Egypt, allowing easy future uploads of the library’s collections. Other categories to which the collection was linked include Image sources of Belgium and Images from libraries in Belgium; with each glass diapositive individually assigned to more specific categories related to its content such as Tod Temple of Montu in Tod and Senusret III. The attribution of categories to the glass diapositives, aims to collect various data sources centrally and as such allows a larger public, existing of both expert and non-expert users, to be reached.

Finally, the link between Wikimedia Commons and Wikidata had to be established prior to pushing the data to Wikimedia. To this end, the Wikidata QID of all items was extracted in OpenRefine using the reconciliation function and added to a custom Wikimedia Commons template using a regular expression. Not only was this action performed for the title of the glass diapositives, but information such as the collection or current location of the slide was connected as well. Small errors that occurred during upload were solved using the Cat-a-lot gadget of Wikimedia Commons. An example of a successful upload to Wikimedia Commons can be seen in figure 8. As this connection is bilateral, in addition to adding the Wikidata identifiers to Wikimedia Commons, the Wikidata entries had to be enhanced with the Wikimedia Commons filenames in the Wikidata property Image (P18). Although it is possible to update the previously created Wikibase scheme and push the data once more, as explained by meemoo in their webinar[5], a more efficient way of adding metadata to the Wiki Environment is proposed. By creating a .XLSX file with Quickstatements, and running this instead, only newly created metadata will be considered.

To further improve the accessibility, searchability, and quality of information offered, structured data should be added on Wikimedia Commons. This allows the metadata to be both human- and machine-readable. Although it is not yet possible to add structured data unique to each slide in batch and it is too time consuming and error-prone to do this manually for each entry, multiple projects are currently ongoing and will hopefully allow this in the future. For now, the AC/DC tool or Add to Commons/Descriptive Claims was used to add fixed values to large selections of files, such as information on copyright status or collection details (see figure 9).

In order to already prepare the metadata of KU Leuven Libraries for said advancements, Named Entity Recognition (NER) was performed, where keywords describing the content of each glass diapositive were extracted from the title and subtitle of all records. Multiple experiments were done to determine the best way to carry out NER for this collection. Eventually, the Dandelion API service was chosen as it can easily be implemented in OpenRefine using the named entity recognition extension developed by the Free Your Metadata project[6]. The best results were achieved on the English translations created before (see figure 10).

Proposed Workflow
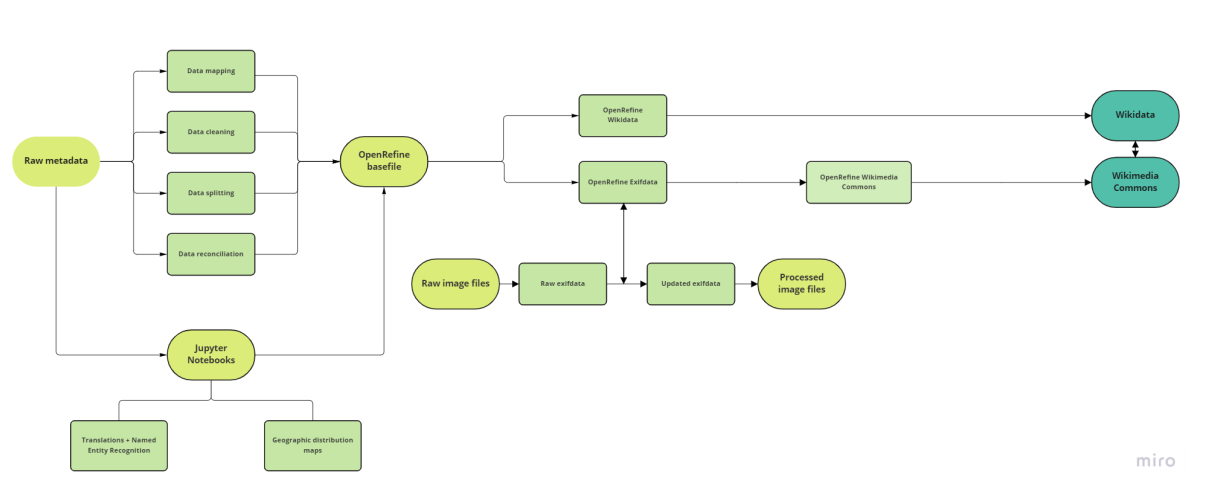
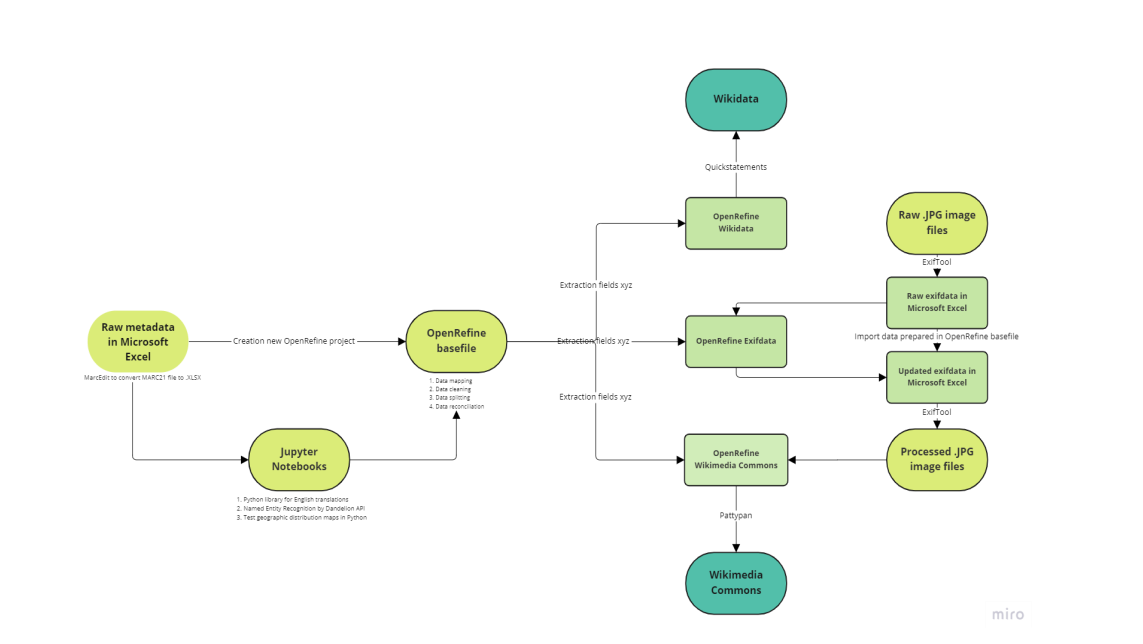
Next to the upload of a selection of glass diapositives to the Wiki Environment, the most important outcome of this internship was the creation of a guideline for data upload to be implemented in KU Leuven Libraries’ existing workflows, illustrated in the flowchart below (see figure 11) and shortly discussed here. All actions proposed need to be considered part of an iterative process where different phases can be repeated multiple times and revisited if necessary. Figure 12 provides an overview of all files created and their relation to each other. More information and recommendations can be found in the report written during the course of this internship.
Prior to data publication, the metadata quality and data consistency should be assessed and improved using OpenRefine for data cleaning. The quality of the data mapping performed, with the attribution of the correct Wikidata properties and Wikimedia Commons templates, is highly influential to the level of data dissemination achieved and therefore plays a key role in the process. Once mapping is completed, the collection has to be prepared accordingly by the creation of a Wikibase schema in OpenRefine, an export to Quickstatements, and an eventual push to Wikidata. To ease this process, prepared columns should be placed at the end of the OpenRefine project, following the structure of the metadata after upload and being separated by platform and/or use. Using OpenRefine, the exifdata present in the images must be expanded and prepared to be pushed with ExifTool, after which upload to Wikimedia Commons can start. To do so, the metadata is extracted from the images into an XLSX file using Pattypan. After updating the XLSX file with the preferred information, the metadata is validated and uploaded to Wikimedia Commons with said tool. The last step of the process entails the release of a VRTS statement on the copyright status and license of the uploaded images, which can be achieved through the interactive release generator.
Lessons learned
By uploading the images and their associated metadata to the Wiki Environment, not only the goal of data dissemination is reached but KU Leuven Libraries responds to the ever-increasing importance of linked data usage in the GLAM sector. As mentioned previously, Wikidata and Wikimedia Commons, in this regard, act as linked data or authority hubs where data reconciliation and the existence of templates ensure the use of a single structured vocabulary across the Wiki Environment by institutions worldwide, contrary to the use of library-specific protocols. This does not only aid the searchability of the data by playing into machine-readability and data linkage, but greatly enhances the usability for the (general) public, who can now simultaneously look throughout a large number of collections using a single uniform search term.
My internship demonstrated not only the (dis)advantages of the use of the Wiki Environment and the value that programming languages have in metadata enrichment and amelioration, but showed that optimizing the data upload requires a substantial amount of time. It is therefore crucial that KU Leuven Libraries draws up a balance between results achieved and time invested, amongst others by keeping track of user statistics over prolonged periods of time. Not only the workflow shortly introduced here can be applied on other digitized collections. The automatic translation of metadata and named entity extraction performed during this internship could also be performed, whether or not upload to the Wiki Environment is intended.
Link to the collection
[1] Tharani, K. ‘Much More than a Mere Technology: A Systematic Review of Wikidata in Libraries’, The Journal of Academic Librarianship 47 (2021): 102326.
[2] Wikidata 10/07/2022, ‘Wikidata: Identifiers’, consulted 13th of August 2022 via https://www.wikidata.org/wiki/Wikidata:Identifiers.
[3] Europeana 17/09/2020, ‘Why Data Partners should Link their Vocabulary to Wikidata: A New Case Study’, consulted 23rd of March 2022 via https://pro.europeana.eu/post/why-data-partners-should-link-their-vocabulary-to-wikidata-a-new-case-study; van Veen, T., ‘Wikidata: From “an” Identifier to “the” Identifier’, Information Technology and Llibraries 38 (2019): 72.
[4] Meemoo, Vlaams instituut voor het archief 27/04/2021, ‘Wikimedia upload 4: metadata embedden met exiftool’, consulted 15th of March 2022 via https://youtu.be/W0v0Iwde86I; Saenko A., Donvil S. and Vanderperren N. 09/03/2022, ‘Publicatie: Upload van reproducties van kunstwerken uit het Groeningemuseum op Wikimedia Commons’, consulted 15th of March 2022 via https://www.projectcest.be/wiki/Publicatie:Upload_van_reproducties_van_kunstwerken_uit_het_Groeningemuseum_op_Wikimedia_Commons.
[5] Meemoo 27/04/2021 34:00, ‘Wikimedia upload 5: beelden uploaden met Pattypan en koppelen met Wikidata’, consulted 20th of March 2022 via https://www.youtube.com/watch?v=vkY41FVhmxk.
[6] Free Your Metadata 2016, ‘Named entity recognition’, consulted 5th of July 2022 via https://freeyourmetadata.org/named-entity-extraction/; Ruben Verborgh 21/06/2017, ‘Refine-NER-Extension’, consulted 5th of July 2022 via https://github.com/RubenVerborgh/Refine-NER-Extension.

{kind=link}